

【点击观看视频】Go work stealing 机制?
# 概念
当线程M⽆可运⾏的G时,尝试从其他M绑定的P偷取G,减少空转,提高了线程利用率(避免闲着不干活)。
当从本线程绑定 P 本地 队列、全局G队列、netpoller都找不到可执行的 g,会从别的 P 里窃取G并放到当前P上面。
从netpoller 中拿到的G是_Gwaiting状态( 存放的是因为网络IO被阻塞的G),从其它地方拿到的G是_Grunnable状态
从全局队列取的G数量:N = min(len(GRQ)/GOMAXPROCS + 1, len(GRQ/2)) (根据GOMAXPROCS负载均衡)
从其它P本地队列窃取的G数量:N = len(LRQ)/2(平分)
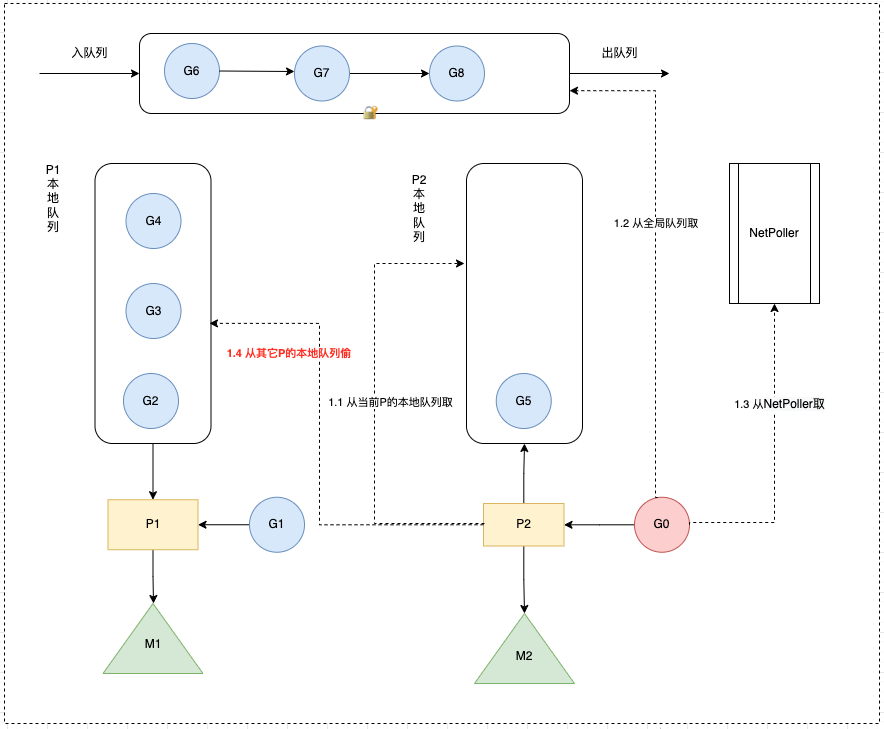
# 窃取流程
源码见runtime/proc.go stealWork函数,窃取流程如下,如果经过多次努力一直找不到需要运行的goroutine则调用stopm进入睡眠状态,等待被其它工作线程唤醒。
选择要窃取的P
从P中偷走一半G
# 选择要窃取的P
窃取的实质就是遍历allp中的所有p,查看其运行队列是否有goroutine,如果有,则取其一半到当前工作线程的运行队列
为了保证公平性,遍历allp时并不是固定的从allp[0]即第一个p开始,而是从随机位置上的p开始,而且遍历的顺序也随机化了,并不是现在访问了第i个p下一次就访问第i+1个p,而是使用了一种伪随机的方式遍历allp中的每个p,防止每次遍历时使用同样的顺序访问allp中的元素
offset := uint32(random()) % nprocs
coprime := 随机选取一个小于nprocs且与nprocs互质的数
const stealTries = 4 // 最多重试4次
for i := 0; i < stealTries; i++ {
for i := 0; i < nprocs; i++ {
p := allp[offset]
从p的运行队列偷取goroutine
if 偷取成功 {
break
}
offset += coprime
offset = offset % nprocs
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到只要随机数不一样,偷取p的顺序也不一样,但可以保证经过nprocs次循环,每个p都会被访问到。
# 从P中偷走一半G
源码见runtime/proc.go runqsteal函数:
挑选出盗取的对象p之后,则调用runqsteal盗取p的运行队列中的goroutine,runqsteal函数再调用runqgrap从p的本地队列尾部批量偷走一半的g
为啥是偷一半的g,可以理解为负载均衡
func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&_p_.runqtail) // load-acquire, synchronize with the producer
n := t - h //计算队列中有多少个goroutine
n = n - n/2 //取队列中goroutine个数的一半
if n == 0 {
......
return ......
}
return n
}
}
2
3
4
5
6
7
8
9
10
11
12
13