

【点击观看视频】Go map如何查找?
Go 语言中读取 map 有两种语法:带 comma 和 不带 comma。当要查询的 key 不在 map 里,带 comma 的用法会返回一个 bool 型变量提示 key 是否在 map 中;而不带 comma 的语句则会返回一个 value 类型的零值。如果 value 是 int 型就会返回 0,如果 value 是 string 类型,就会返回空字符串。
// 不带 comma 用法
value := m["name"]
fmt.Printf("value:%s", value)
// 带 comma 用法
value, ok := m["name"]
if ok {
fmt.Printf("value:%s", value)
}
2
3
4
5
6
7
8
9
map的查找通过生成汇编码可以知道,根据 key 的不同类型/返回参数,编译器会将查找函数用更具体的函数替换,以优化效率:
| key 类型 | 查找 |
|---|---|
| uint32 | mapaccess1_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint32 | mapaccess2_fast32(t maptype, h hmap, key uint32) (unsafe.Pointer, bool) |
| uint64 | mapaccess1_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| uint64 | mapaccess2_fast64(t maptype, h hmap, key uint64) (unsafe.Pointer, bool) |
| string | mapaccess1_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
| string | mapaccess2_faststr(t maptype, h hmap, ky string) (unsafe.Pointer, bool) |
# 查找流程
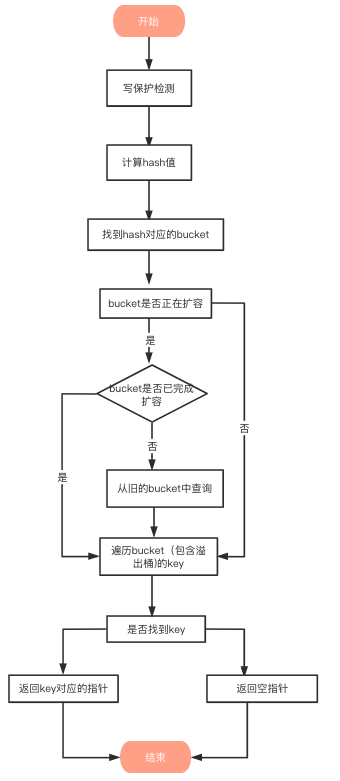
- 写保护监测
函数首先会检查 map 的标志位 flags。如果 flags 的写标志位此时被置 1 了,说明有其他协程在执行“写”操作,进而导致程序 panic,这也说明了 map 不是线程安全的
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
2
3
- 计算hash值
hash := t.hasher(key, uintptr(h.hash0))
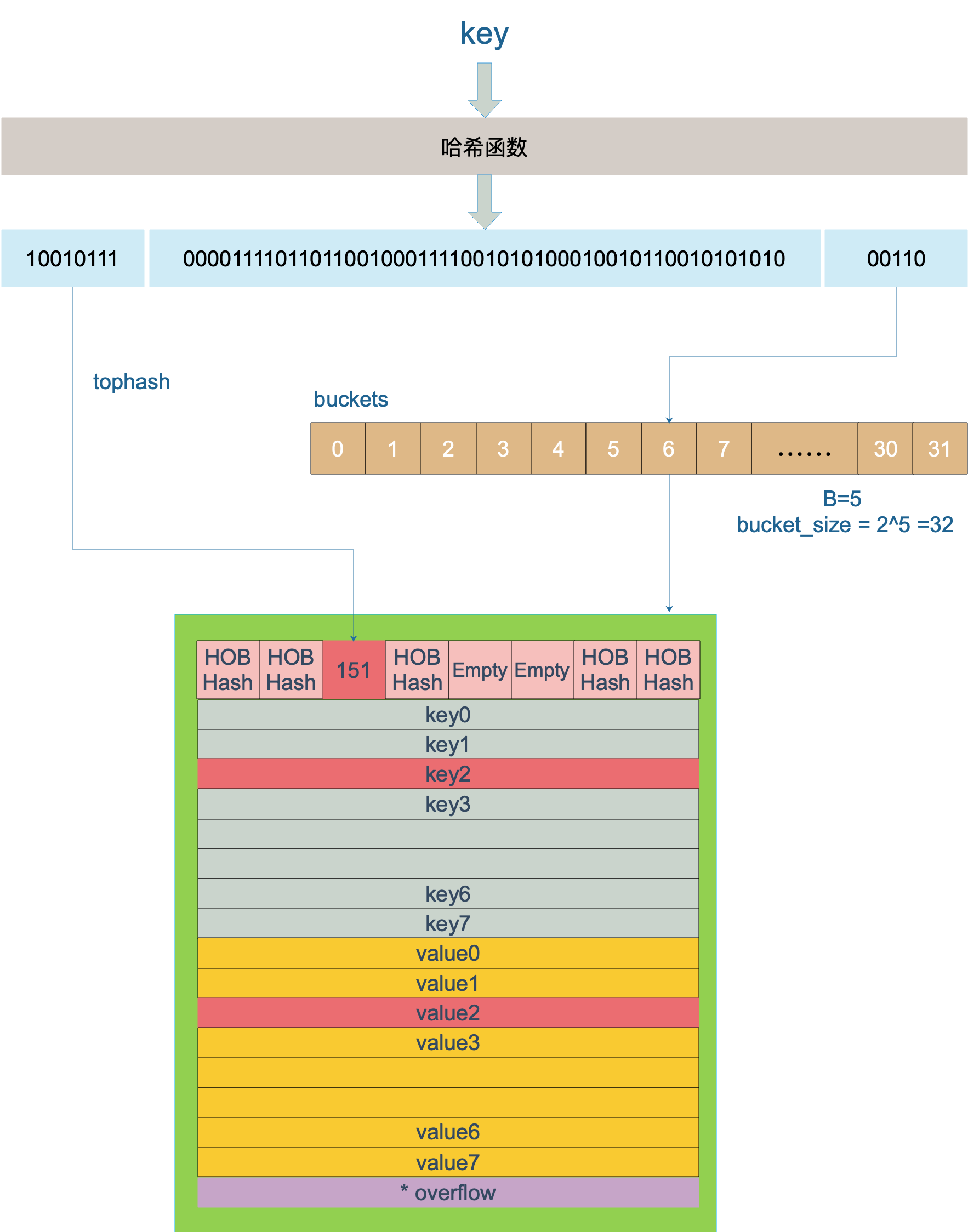
key经过哈希函数计算后,得到的哈希值如下(主流64位机下共 64 个 bit 位), 不同类型的key会有不同的hash函数
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
- 找到hash对应的bucket
bucket定位:哈希值的低B个bit 位,用来定位key所存放的bucket
如果当前正在扩容中,并且定位到的旧bucket数据还未完成迁移,则使用旧的bucket(扩容前的bucket)
hash := t.hasher(key, uintptr(h.hash0))
// 桶的个数m-1,即 1<<B-1,B=5时,则有0~31号桶
m := bucketMask(h.B)
// 计算哈希值对应的bucket
// t.bucketsize为一个bmap的大小,通过对哈希值和桶个数取模得到桶编号,通过对桶编号和buckets起始地址进行运算,获取哈希值对应的bucket
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 是否在扩容
if c := h.oldbuckets; c != nil {
// 桶个数已经发生增长一倍,则旧bucket的桶个数为当前桶个数的一半
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
// 计算哈希值对应的旧bucket
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果旧bucket的数据没有完成迁移,则使用旧bucket查找
if !evacuated(oldb) {
b = oldb
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
4. 遍历bucket查找
tophash值定位:哈希值的高8个bit 位,用来快速判断key是否已在当前bucket中(如果不在的话,需要去bucket的overflow中查找)
用步骤2中的hash值,得到高8个bit位,也就是10010111,转化为十进制,也就是151
top := tophash(hash)
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
2
3
4
5
6
7
8
上面函数中hash是64位的,sys.PtrSize值是8,所以top := uint8(hash >> (sys.PtrSize*8 - 8))等效top = uint8(hash >> 56),最后top取出来的值就是hash的高8位值
在 bucket 及bucket的overflow中寻找tophash 值(HOB hash)为 151* 的 槽位,即为key所在位置,找到了空槽位或者 2 号槽位,这样整个查找过程就结束了,其中找到空槽位代表没找到。
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 未被使用的槽位,插入
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 找到tophash值对应的的key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
return e
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
5. 返回key对应的指针
如果通过上面的步骤找到了key对应的槽位下标 i,我们再详细分析下key/value值是如何获取的:
// keys的偏移量
dataOffset = unsafe.Offsetof(struct{
b bmap
v int64
}{}.v)
// 一个bucket的元素个数
bucketCnt = 8
// key 定位公式
k :=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))
// value 定位公式
v:= add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
2
3
4
5
6
7
8
9
10
11
12
13
14
bucket 里 keys 的起始地址就是 unsafe.Pointer(b)+dataOffset
第 i 个下标 key 的地址就要在此基础上跨过 i 个 key 的大小;
而我们又知道,value 的地址是在所有 key 之后,因此第 i 个下标 value 的地址还需要加上所有 key 的偏移。