【点击观看视频】Go map的底层实现原理?
Go中的map是一个指针,占用8个字节,指向hmap结构体
源码包中src/runtime/map.go定义了hmap的数据结构:
hmap包含若干个结构为bmap的数组,每个bmap底层都采用链表结构,bmap通常叫其bucket

hmap结构体
// A header for a Go map.
type hmap struct {
count int
// 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8
// 状态标志(是否处于正在写入的状态等)
B uint8
// buckets(桶)的对数
// 如果B=5,则buckets数组的长度 = 2^B=32,意味着有32个桶
noverflow uint16
// 溢出桶的数量
hash0 uint32
// 生成hash的随机数种子
buckets unsafe.Pointer
// 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
oldbuckets unsafe.Pointer
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
nevacuate uintptr
// 表示扩容进度,小于此地址的buckets代表已搬迁完成。
extra *mapextra
// 存储溢出桶,这个字段是为了优化GC扫描而设计的,下面详细介绍
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
bmap结构体
bmap 就是我们常说的“桶”,一个桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果的低B位是相同的,关于key的定位我们在map的查询中详细说明。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
// len为8的数组
// 用来快速定位key是否在这个bmap中
// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}
2
3
4
5
6
7
上面bmap结构是静态结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{
tophash [8]uint8
keys [8]keytype
// keytype 由编译器编译时候确定
values [8]elemtype
// elemtype 由编译器编译时候确定
overflow uintptr
// overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
2
3
4
5
6
7
8
9
tophash就是用于实现快速定位key的位置,在实现过程中会使用key的hash值的高8位作为tophash值,存放在bmap的tophash字段中
tophash字段不仅存储key哈希值的高8位,还会存储一些状态值,用来表明当前桶单元状态,这些状态值都是小于minTopHash的
为了避免key哈希值的高8位值和这些状态值相等,产生混淆情况,所以当key哈希值高8位若小于minTopHash时候,自动将其值加上minTopHash作为该key的tophash。桶单元的状态值如下:
emptyRest = 0 // 表明此桶单元为空,且更高索引的单元也是空
emptyOne = 1 // 表明此桶单元为空
evacuatedX = 2 // 用于表示扩容迁移到新桶前半段区间
evacuatedY = 3 // 用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 // 用于表示此单元已迁移
minTopHash = 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
2
3
4
5
6
7
8
9
10
11
12
13
14
mapextra结构体
当map的key和value都不是指针类型时候,bmap将完全不包含指针,那么gc时候就不用扫描bmap。bmap指向溢出桶的字段overflow是uintptr类型,为了防止这些overflow桶被gc掉,所以需要mapextra.overflow将它保存起来。如果bmap的overflow是*bmap类型,那么gc扫描的是一个个拉链表,效率明显不如直接扫描一段内存(hmap.mapextra.overflow)
type mapextra struct {
overflow *[]*bmap
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
oldoverflow *[]*bma
// oldoverflow 包含扩容时 hmap.oldbuckets 的 overflow 的 bucket
nextOverflow *bmap
// 指向空闲的 overflow bucket 的指针
}
2
3
4
5
6
7
8
总结
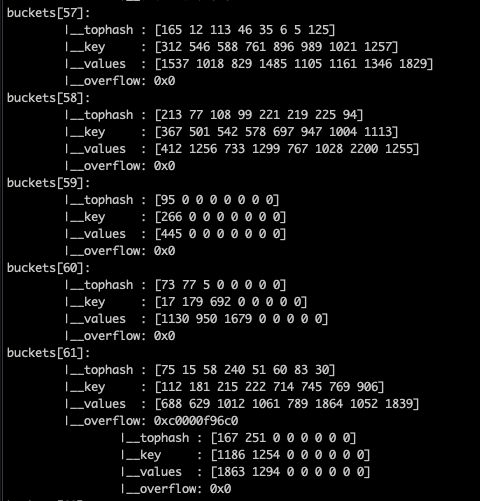
bmap(bucket)内存数据结构可视化如下:
注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式,当key和value类型不一样的时候,key和value占用字节大小不一样,使用key/value这种形式可能会因为内存对齐导致内存空间浪费,所以Go采用key和value分开存储的设计,更节省内存空间